
New blog!
I will no longer be posting to this blog, instead I will be using http://mlbernauer.bitbucket.org/
I will no longer be posting to this blog, instead I will be using http://mlbernauer.bitbucket.org/

Many data sets are inherently dirty, they contain misspellings, missing data, erroneous values, etc. This is particularly true for data sets created by people typing information into forms or spreadsheets […]
I’ve been collecting FDA Adverse Event Reporting (FAERS) data for quite some time now in hopes of using it in various pharmacovigilance projects. The FDA makes this data available to […]
A collection of US colleges of pharmacy created by scraping the U.S. News Best Grad Schools list. CSV
Recently, I created a few R functions for querying and retrieving results from NCBI using E-utilities. Instead of copying these functions into my working directory each time I wanted to […]
Note: Source code can be obtained here I’ve posted on using PubMed as a resource for text analysis before (here and here). For those projects I would download PubMed results […]
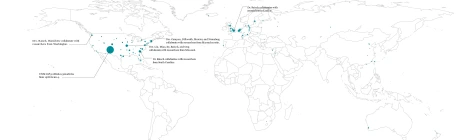
I was interested in seeing what institutions frequently collaborate with researchers from UNM College of Pharmacy. Using PubMed publication records I was able to create the figure below which shows […]
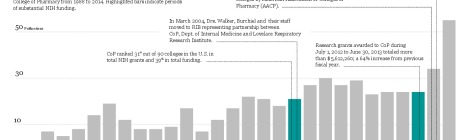
PubMed is a fantastic database for biomedical literature and contains over 24.4 million entries to date. One of PubMed’s greatest features is it’s ability to allow users to create custom […]
NOTE: The source code for the R module can be found here I often use the Medline module from the Biopython library for parsing and extracting data from PubMed Medline […]
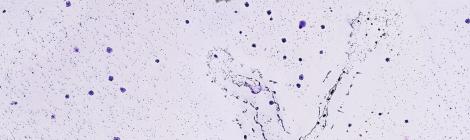
NOTE: The IPython notebook used in this project can be found here. Introduction: I used to work in a cancer lab at Lovelace Respiratory Research Institute where one of my […]
